Hva er skraping av nettet? Hvordan samle inn data fra nettsteder
Annonse
Nettskrapere samler automatisk informasjon og data som vanligvis bare er tilgjengelige ved å besøke et nettsted i en nettleser. Ved å gjøre dette autonomt åpner skraping av nett for en verden av muligheter innen data mining, dataanalyse, statistisk analyse og mye mer.
Hvorfor nettskraping er nyttig
Vi lever i en dag og alder der informasjon er lettere tilgjengelig enn noen annen tid. Infrastrukturen som er brukt for å levere akkurat disse ordene du leser, er en kanal for mer kunnskap, mening og nyheter enn noen gang har vært tilgjengelig for mennesker i historien til mennesker.
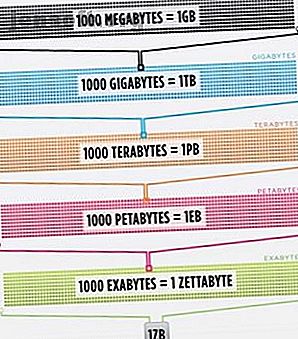
Så mye at faktisk den smarte personens hjerne, forbedret til 100% effektivitet (noen burde lage en film om det), fremdeles ikke ville være i stand til å holde 1/1000-del av dataene som er lagret på internett i USA alene .
Cisco estimerte i 2016 at trafikken på internett overskred en zettabyte, som er 1.000.000.000.000.000.000.000 byte, eller en sextillion byte (fortsett, fnise på sextillion). En zettabyte er omtrent fire tusen år med streaming av Netflix. Det vil være ekvivalent med hvis du, uforstandige lesere, skulle streame Office fra start til slutt uten å stoppe 500 000 ganger.

All denne informasjonen og informasjonen er veldig skremmende. Ikke det hele stemmer. Ikke mye av det er relevant for hverdagen, men flere og flere enheter leverer denne informasjonen fra servere over hele verden rett i øynene og i hjernen vår.
Ettersom våre øyne og hjerner ikke virkelig kan håndtere all denne informasjonen, har skraping av nettopp dukket opp som en nyttig metode for å samle inn data programmisk fra internett. Nettskraping er det abstrakte begrepet for å definere handlingen for å trekke ut data fra nettsteder for å lagre det lokalt.
Tenk på en type data, og du kan sannsynligvis samle dem ved å skrape nettet. Eiendomslister, sportsdata, e-postadresser til bedrifter i ditt område, og til og med tekstene fra favorittartisten din, kan alle oppsøkes og lagres ved å skrive et lite manus.
Hvordan får en nettleser nettdata?
For å forstå nettskrapere, må vi forstå hvordan nettet fungerer først. For å komme til dette nettstedet, skrev du enten "makeuseof.com" i nettleseren din, eller du klikket på en kobling fra en annen webside (fortell oss hvor, alvorlig vi vil vite). Uansett er de neste par trinnene de samme.
Først tar nettleseren nettadressen du skrev inn eller klikket på (Pro-tips: hold musepekeren over lenken for å se URL-en nederst i nettleseren før du klikker på den for å unngå å bli punk'd) og danne en "forespørsel" om å sende til en server. Serveren vil deretter behandle forespørselen og sende svar tilbake.
Serverens svar inneholder HTML, JavaScript, CSS, JSON og andre data som er nødvendige for å tillate nettleseren din å danne en webside for din opplevelse.
Inspiserer nettelementer
Moderne nettlesere tillater oss noen detaljer angående denne prosessen. I Google Chrome på Windows kan du trykke på Ctrl + Shift + I eller høyreklikke og velge Inspisere . Vinduet vil da presentere en skjerm som ser ut som følgende.

En faneliste med alternativer linjer øverst i vinduet. Av interesse akkurat nå er fanen Nettverk . Dette vil gi detaljer om HTTP-trafikken som vist nedenfor.

Nederst til høyre ser vi informasjon om HTTP-forespørselen. URLen er det vi forventer, og "metoden" er en HTTP "GET" -forespørsel. Statuskoden fra svaret er oppført som 200, noe som betyr at serveren så forespørselen som gyldig.
Under statuskoden er ekstern adresse, som er den offentlige IP-adressen til makeuseof.com-serveren. Klienten får denne adressen via DNS-protokollen Hvorfor endre DNS-innstillinger øker Internetthastigheten din Hvorfor endre DNS-innstillingene øker Internetthastigheten din Endre DNS-innstillingene dine er en av de mindre justeringene som kan ha stor avkastning på den daglige internetthastigheten. Les mer .
Den neste delen viser detaljer om svaret. Svarhodet inneholder ikke bare statuskoden, men også datatypen eller innholdet som svaret inneholder. I dette tilfellet ser vi på “tekst / html” med en standardkoding. Dette forteller oss at svaret bokstavelig talt er HTML-koden for å gjengi nettstedet.

Andre typer svar
I tillegg kan servere returnere dataobjekter som svar på en GET-forespørsel, i stedet for bare HTML for websiden å gjengi. Nettstedets applikasjonsprogrammeringsgrensesnitt (eller API) Hva er API-er, og hvordan endrer åpne API-er Internett Hva er API-er, og hvordan endrer åpne API-er Internett Har du noen gang lurt på hvordan programmer på datamaskinen din og nettstedene du besøker "talk" til hverandre? Les mer bruker vanligvis denne typen utveksling.
Les gjennom fanen Nettverk som vist ovenfor, kan du se om det er denne typen utveksling. Når du undersøker CrossFit Open Leaderboard, vises forespørselen om å fylle tabellen med data.

Ved å klikke over til svaret vises JSON-data i stedet for HTML-koden for gjengivelse av nettstedet. Data i JSON er en serie etiketter og verdier, i en lagvis, skissert liste.

Å manuelt analysere HTML-kode eller gå gjennom tusenvis av nøkkel / verdipar med JSON er mye som å lese Matrix. Ved første øyekast ser det ut som søppel. Det kan være for mye informasjon til å avkode den manuelt.
Nettskrapere til unnsetning!
Før du ber om den blå pillen for å få pokker ut herfra, bør du vite at vi ikke trenger å avkode HTML-kode manuelt! Uvitenhet er ikke lykke, og denne biffen er deilig.
En webskraper kan utføre disse vanskelige oppgavene for deg. Scrapestack API gjør det enkelt å skrape nettsteder for data. Scrapestack API gjør det enkelt å skrape nettsteder for data Leter du etter en kraftig og rimelig webskraper? Scrapestack API er gratis å starte og tilbyr mange nyttige verktøy. Les mer . Skrapingsrammer er tilgjengelige på Python, JavaScript, Node og andre språk. En av de enkleste måtene å begynne å skrape på er ved å bruke Python og Beautiful Soup.
Skrape et nettsted med Python
Å komme i gang tar bare noen få linjer med kode, så lenge du har Python og BeautifulSoup installert. Her er et lite skript for å få en nettside kilde og la BeautifulSoup evaluere det.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Vi sender ganske enkelt en GET-forespørsel til en URL og legger svaret inn i et objekt. Skrive ut objektet viser HTML-kildekoden til URL-en. Prosessen er akkurat som om vi manuelt gikk til nettstedet og klikket på View Source .
Spesielt er dette et nettsted som legger ut treninger i CrossFit-stil hver dag, men bare en per dag. Vi kan bygge skraperen vår for å få treningen hver dag, og deretter legge den til en samlet liste over treningsøkter. I hovedsak kan vi lage en tekstbasert historisk database med treningsøkter vi lett kan søke gjennom.
Magien med BeaufiulSoup er muligheten til å søke gjennom all HTML-koden ved hjelp av den innebygde findAll () -funksjonen. I dette spesifikke tilfellet bruker nettstedet flere "sqs-block-content" -koder. Derfor må skriptet gå gjennom alle disse kodene og finne den som er interessant for oss.
I tillegg er det en rekke
tagger i seksjonen. Skriptet kan legge til all teksten fra hver av disse kodene til en lokal variabel. For å gjøre dette, legg til en enkel sløyfe til skriptet:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! En nettskrape er født.
Skaler opp skraping
Det finnes to stier for å komme videre.
En måte å utforske skraping på nettet er å bruke verktøy som allerede er bygget. Web Scraper (flott navn!) Har 200 000 brukere og er enkel å bruke. Parse Hub lar også brukere eksportere skrapede data til Excel og Google Sheets.
I tillegg tilbyr Web Scraper en Chrome-plugin-modul som hjelper til med å visualisere hvordan et nettsted bygges. Det beste av alt, å dømme etter navn, er OctoParse, en kraftig skrape med et intuitivt grensesnitt.
Til slutt, nå som du vet bakgrunnen for skraping av nettet, å heve din egen lille nettskraper for å kunne gjennomgå og kjøre. Hvordan bygge en grunnleggende webcrawler for å trekke informasjon fra et nettsted Hvordan bygge en grunnleggende webcrawler for å trekke informasjon fra en Nettsted Har du noen gang ønsket å hente informasjon fra et nettsted? Du kan skrive en gjennomsøker for å navigere på nettstedet og trekke ut det du trenger. Les mer på egenhånd er en morsom innsats.
Utforsk mer om: Python, skraping av nett.

